这是在公司分享的文本整理,删除敏感数据后的 PPT
前端的痛点
我们的应用部署在客户端,当出现问题,不像服务端,问题发生在我们自己的机器上,前端没有用户日志,用户操作对我们来说是一个黑盒,只能通过提前做一些埋点或者用户反馈去推测问题发生并验证。 前端环境过于复杂,不同型号的手机,不同的系统版本,不同的浏览器内核,不同的网络环境,如果不幸遇到偶发性问题, 复现就变的难上加难,更不用说 debug。
所以我们需要一些可供回溯用户行为的日志去分析
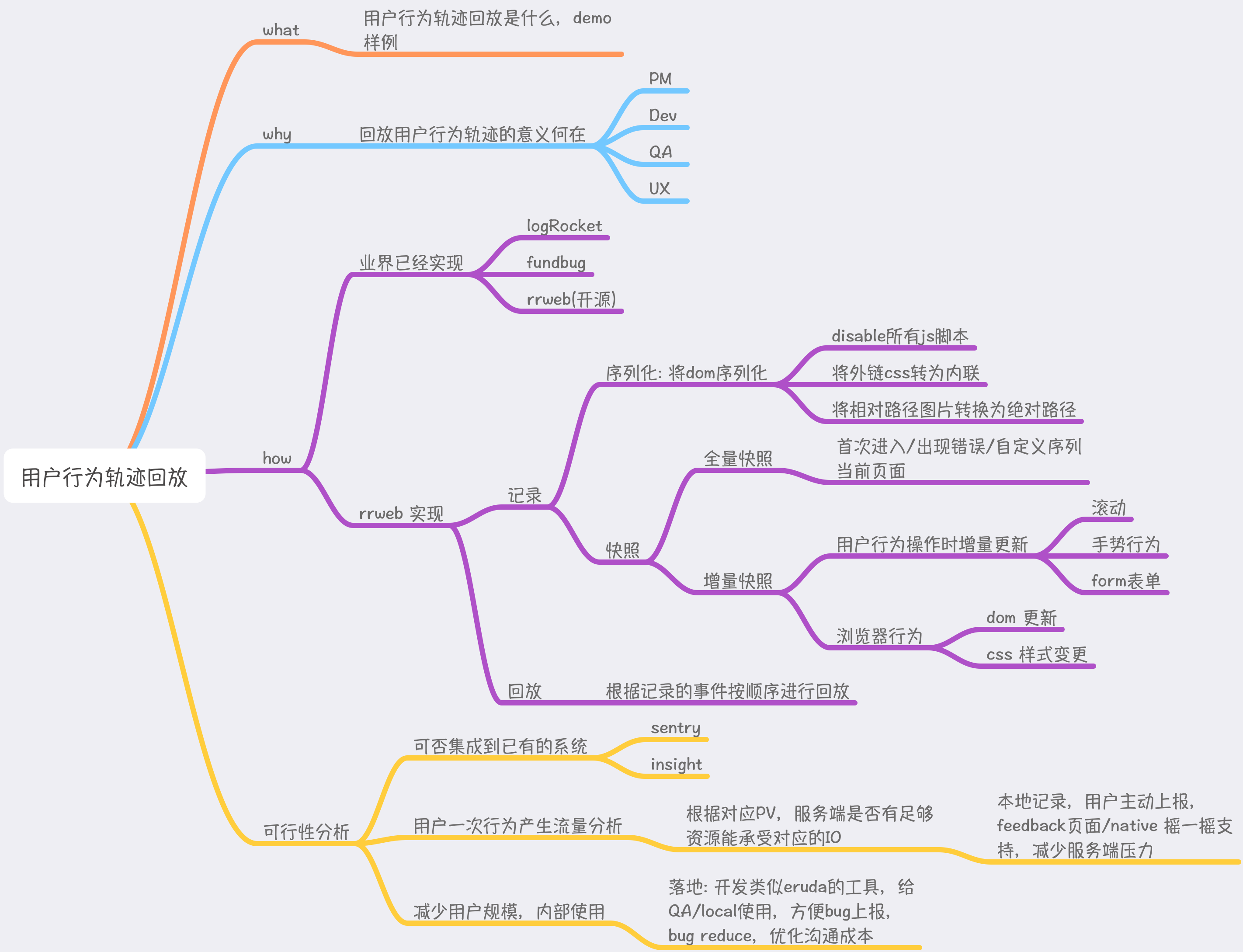
轨迹回放是什么
业界比较成熟的系统有 sentry, logRocket, rrweb。
sentry
sentry 是非常流行的错误监控系统,可用于 c++/Go/python/js 等各种语言,js 接入时,sentry 会在特定时机(用户手动上报/前端发生错误时)上报当前环境的上下文信息,包括一段用户的行为日志
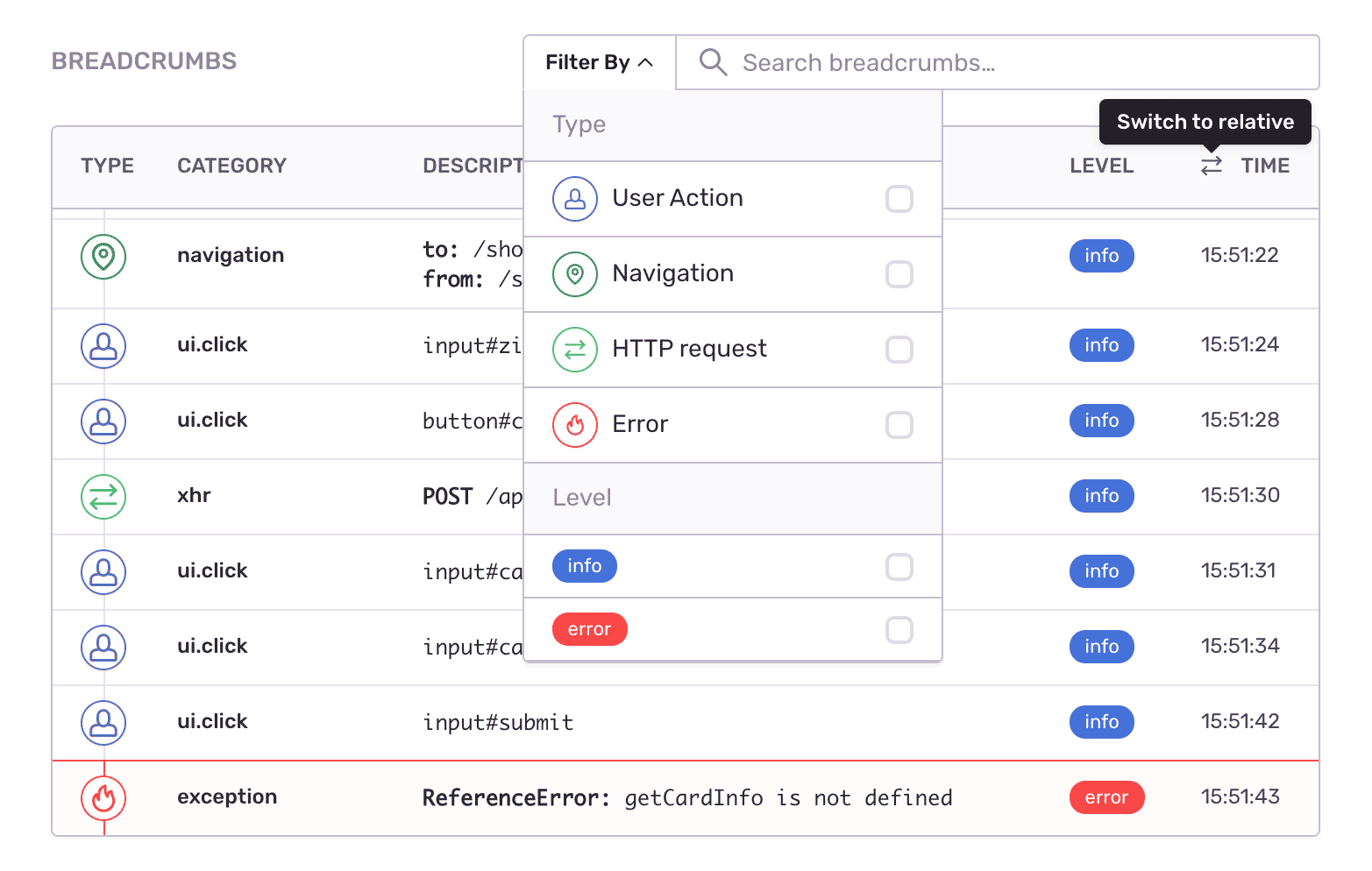
通过完善配置或者集成插件等,可以实现 sourcemap 分析,数据可视化分析等。使用 sentry 能在某种意义上解决问题,在 sentry 上观测到问题后,通过代码分析发现问题出现的原因。前端探索无止尽,sentry 还是有一些不甚让人满意的地方
- 上报的信息过于冗杂,很难分组
- 在需要上报的地方需要额外代码侵入支持
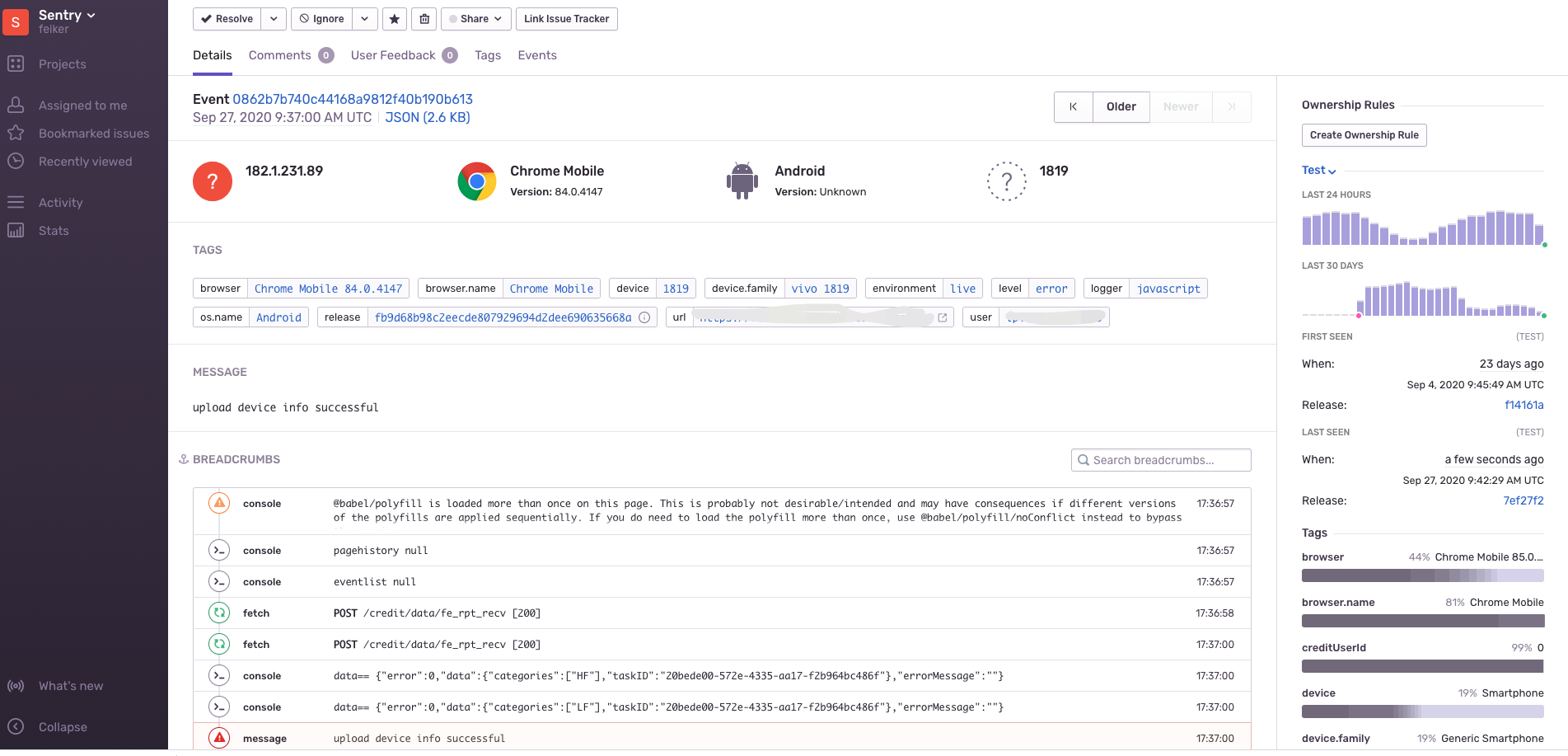
logRocket & rrweb
logRocket & rrweb 提供另外一种可能,通过预埋 sdk,通过完善记录用户行为的操作日志,包括手势行为,交互行为等引起的各种 dom 变动,网络变动等,在特定时机上报到 server 端,通过拉取 server 端相关日志重建用户侧的行为,通过类似视频的形式回放。
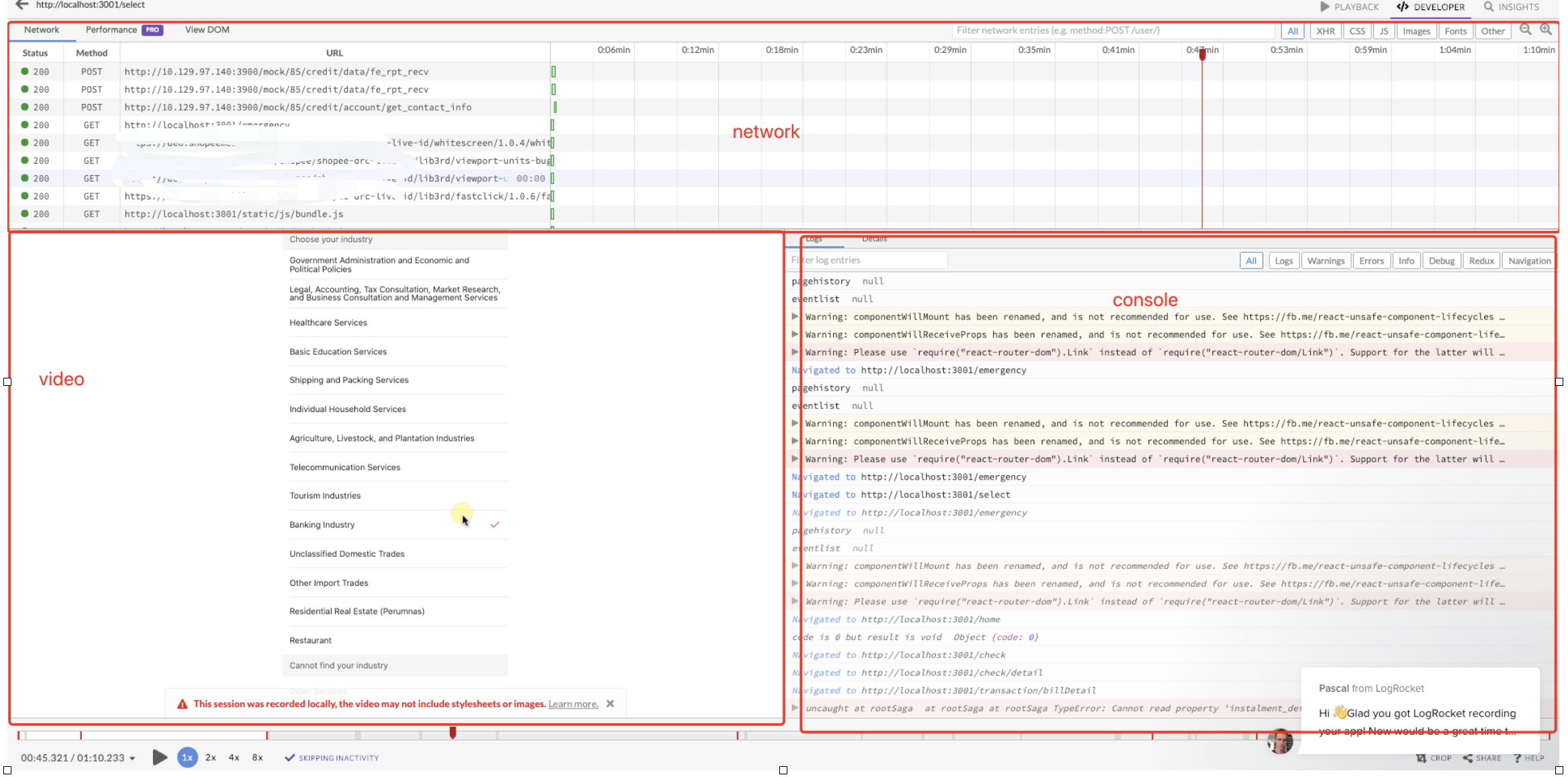
这个是 logRocket 的截图,logRocket 的回放平台包括了用户的整个行为回放,用户机器的 console 输出,网络请求等,甚至可以审查 dom 元素。
做用户行为轨迹回放的意义
我们做一套东西,非常关注的是投入产出比,做这个东西到底有没有必要,也就是说做回放的意义是什么
For Developers
- Reproduce Bug, 实现远程 debug
- 追溯线上的用户问题
For PM
产品经理最关心的是什么,用户!用户行为回放给 PM 提供了最真实最珍贵的第一手资料。
- 除了对数据定量分析,提供定性分析能力
- 让用户面对面操作业务的成本高,轨迹回放提供这种能力
- 用户最常登陆的页面?退出率高的原因?操作场景和使用习惯?用户行为轨迹回放给 UX 优化提供最最贴近用户的素材
For QA
- 对 QA 来说,由于测试机器多,遇到 bug 想录屏给 dev 时操作不方便。
- 复现 bug 时,dev 需要 QA 提供账号,复现场景,复现路径,有了行为轨迹回放,we do not need anything!
类似系统的实现(rrweb 为例)
这个录屏系统上传是一系列的用户行为日志,是一段带时间戳的事件文本,而不是真实的视频文件/canavs 图等。以 rrweb 为例,rrweb 主要分为三个组成部分,分别是
- rrweb-snapshot 用于对 dom 打快照,以及根据快照重建页面行为
- rrweb-player 一套类播放器组件
- rrweb 调控中心,用于记录行为日志,以及根据日志重建视频播放

rrweb 的核心设计有
- 序列化
- 增量快照
- 沙盒播放
序列化
真实 DOM 是由浏览器实现的一套标准,它不可被传输,其一个 dom 节点涵盖过多的我们并不关系的数据,所以为了对真实 DOM 打快照并进行传输,rrweb 做了一套自己的序列化。(可以简单理解为真实 DOM 转为虚拟 DOM 再转为一套文本)
<html>
<body>
<header></header>
</body>
</html>会被解析为
{
"type": "Document",
"childNodes": [
{
"type": "Element",
"tagName": "html",
"attributes": {},
"childNodes": [
{
"type": "Element",
"tagName": "head",
"attributes": {},
"childNodes": [],
"id": 3
},
{
"type": "Element",
"tagName": "body",
"attributes": {},
"childNodes": [
{
"type": "Text",
"textContent": "\n ",
"id": 5
},
{
"type": "Element",
"tagName": "header",
"attributes": {},
"childNodes": [
{
"type": "Text",
"textContent": "\n ",
"id": 7
}
],
"id": 6
}
],
"id": 4
}
],
"id": 2
}
],
"id": 1
}内容来自 rrweb 序列化
增量快照
rrweb 并不是对每帧或者每几帧生成一次快照,这里有点 git 的设计,在特定时机生成一次全量快照,在之后的操作过程中,用户的每一次操作生成一条日志,有点类似用户初始代码仓库时 git init 了一下,之后每次提交都commit
增量快照记录的事件包括
-
DOM 变动
- 节点创建、销毁
- 节点属性变化
- 文本变化
-
鼠标移动
- 鼠标交互
- mouse up、mouse down
- click、double click、context menu
- focus、blur
- touch start、touch move、touch end
-
页面或元素滚动
-
视窗大小改变
-
输入
每次变化都会生成一条数据,数据格式为
{
type: EventType;
timeStamp: number;
data: {
}
}详细可以参考 增量快照
沙盒回放
因为现在是需要根据记录的日志去回播生成一个操作序列,代码执行发生在我们自己的容器内,所以我们需要做一些事情比如
- 禁止 script 执行
- 避免链接跳转
- css 等内联图片路径修改
- hover 等样式
- 类播放效果
rrweb 针对性的做了以下处理
- 将 script 标签改为 noscript,并在 iframe 中沙盒播放
- 禁止 a 链接
- 上报时将外部样式改为内联
- 在发生 hover 等交互事件的 dom 元素添加类
- 进度条拖动(分为两个 part,拖动前同步播放,后面异
可行性分析
-
如果有部署 sentry,其实可以通过将 rrweb 生成的日志通过 sentry 上报到 sentry 的 attachments,出现问题时去 attachments 下载
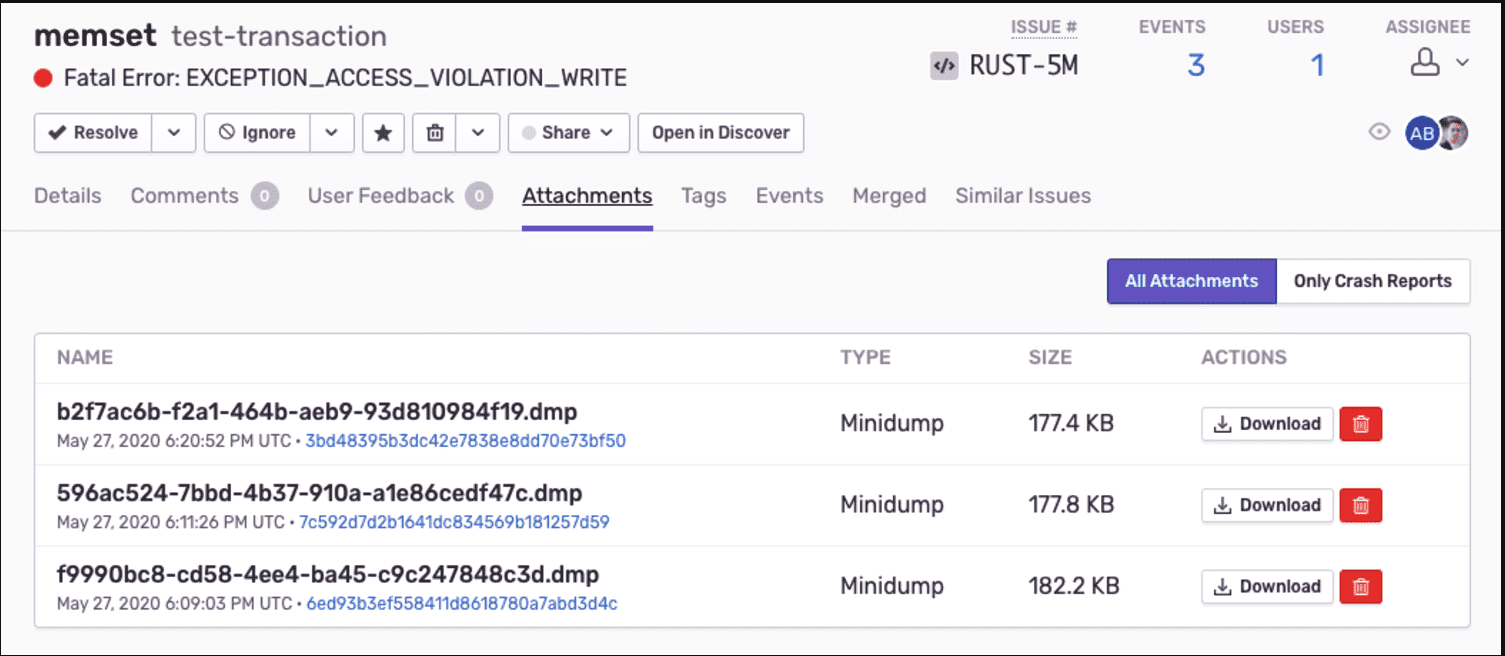
-
对 rrweb 二次开发,自研一套类似 logRocket 的回放平台
经过一些测试,发现用户行为回放的主要瓶颈是日志大小的问题,在复杂 DOM 环境下,简单操作半分钟会生成 1-20M 的数据,对用户流量,服务器的 IO 以及存储是个考验。
针对日志大小的问题,可以考虑以下优化
-
生成数据压缩
-
降低采集频率,失真
-
减少用户规模 数据记录在本地,通过 indexDB/native-bridge 等方式存储在用户本地 提供 feedback 页面,用户出现问题时,一键上传本地日志 远程回溯分析
-
内部使用 开发类似 eruda 的工具,提供 QA/local 使用,方便 bug 上报